Large Language Models (LLMs), Data Privacy and Security: What you Need to Know

What inspired the rise of LLMs and why now?
We have witnessed the remarkable rise of generative AI, powered by vast amounts of pre-trained data within large language models (LLMs). Chat-based interfaces have democratized AI for the general public, which has led us to where we are today.
The underlying LLM technology enables anyone to use prompts using natural language to elicit queries for a specific or intended response. These responses can range from generating text, code, performing tasks, and more. The “natural language understanding” aspect is similar to humans, which previously has not been possible.
We have seen chatbots serve as amazing and effective stock market recommenders, customer support agents, legal case analysts, and even healthcare assistants for complex cases. Many of these entities have sophisticated personalities and conversations while retaining context to complete transactions. The current set of conversational AI is already helping businesses scale with routine tasks like generating invoices, automating returns, researching complex topics, building initial content, and more, saving hours and even days of human work. We are seeing the initial impact of how far automation can be leveraged and the intensity of complex tasks that can be handled with AI. Given these cost savings and efficiency, we will see a widespread use of AI chatbots, agents, and task handlers continue to increase.
With these capabilities, customer data can be easily misused as private conversations. Activity and logs can now be combined with user cookies to allow privacy and security breaches within a simple prompt. As we do not yet have data governance controls for LLMs data protection, a malicious actor can request and receive sensitive data related to a business or person with relative ease.
How LLMs evolve with reinforcement learning with human feedback
LLMs need to be trained on large amounts of data including text, audio, and video. Human input is needed to provide feedback for fine tuning the responses from LLMs, or provide a baseline for correct and incorrect answers. Current LLMs can be trained over hundreds of billions of text documents covering a wide range of situational information, creating a knowledge base that can answer a wide range of questions. This input data set varies and consists of source code, database schema, sales metrics, customer demographics, legal contracts, IT support tickets, patient chats, slack messages, etc.
Today, 80-85% of data is unstructured, and many businesses lack tools to fully utilize this data type. With LLMs, we have an opportunity to effectively make sense of all of this rich unstructured information and can streamline efforts to use it for meaningful purposes.
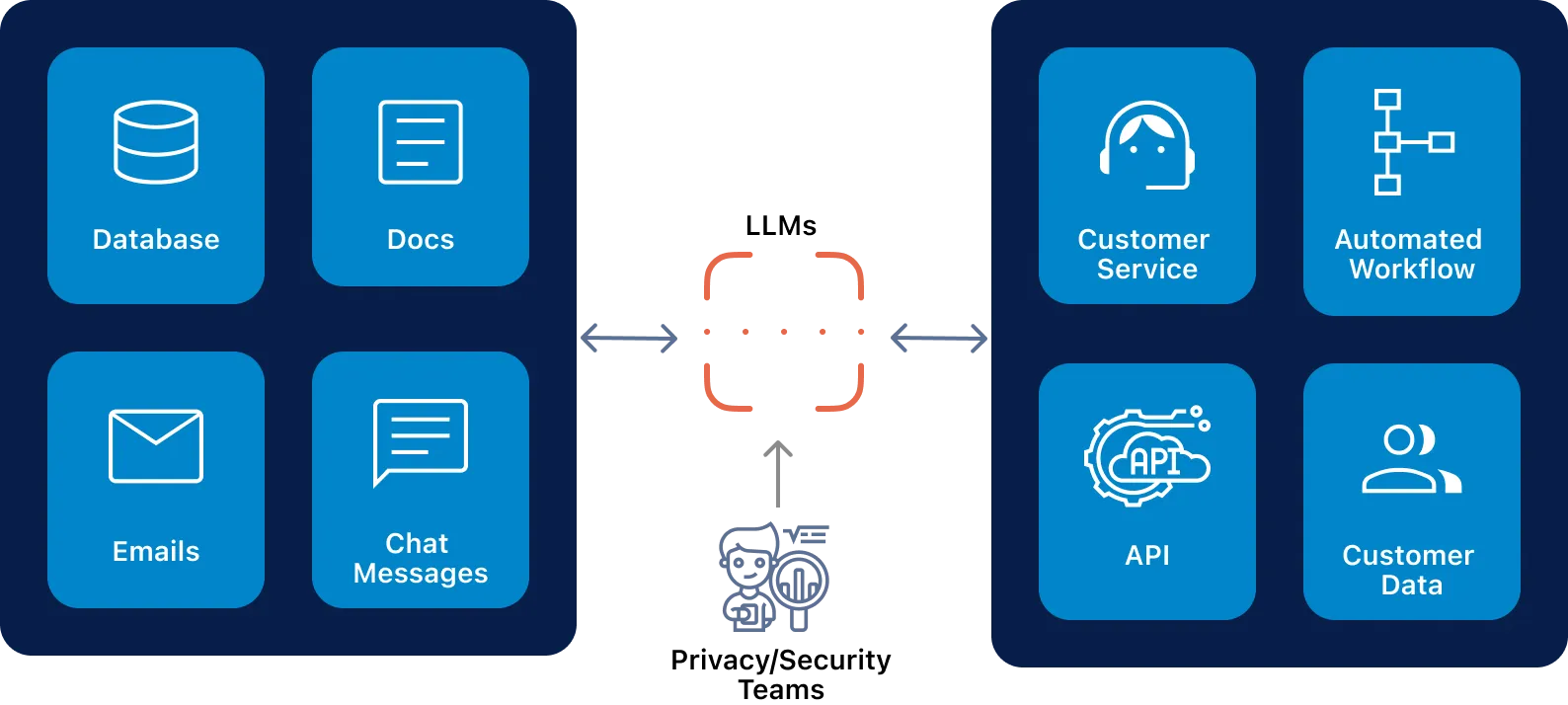
Due to auto-learning capabilities, LLMs can be constantly fed data. The amazing memorization capabilities of LLMs provide us with querying, recommendation, and problem solving capabilities, which have not been possible before. One of the key capabilities offered by LLMs is that of feedback based learning where responses can be augmented and improved over time.
How Businesses interact with LLMs today
Business interact with LLMs in three ways today:
- LLM-hosted platforms directly using an LLM created and maintained by businesses with AI expertise, such as OpenAI.
- Embedded apps via chat/conversational bots within a currently used platform like Google Docs or Office365
- Self hosting model – Either train an LLM from scratch or utilize an Open Source LLM like Alpaca, fine tune the weights and maintain a self hosted version.
As of now, few companies have the cloud infrastructure and AI expertise to create these models from scratch and manage/maintain them for others to consume. Several cloud providers including Amazon Web Services, Google Cloud Platform, and Microsoft Azure are in the process of offering to host LLM based services. Smaller models that can be easily trained and run on a restricted compute environment including mobile devices are also being actively researched.
Today, the majority of businesses use Embedded Application Workflows to interact with LLM prompts within their day-to-day. Tools include word processors, source code checkers, SQL query generators, email responders, customer support, meeting summarizers, trip planners, legal document analyzers, and more. Through these approaches, workflows/bots are able to ingest custom datasets and provide responses against them.
Privacy/Security concerns introduced via LLMs
There are several data security and privacy concerns introduced with LLM usage in a business context. Our intention with this blog series is to provide an overview with guidance towards mitigation or remediation.
The key areas are:
Dark Data Misuse & Discovery
LLMs can consume any kind of input data. A few areas that need attention include dark data in files and emails, orphaned database tables, IP data created by off-boarded employees, privacy data and confidential information about the business itself, and more. Any dark PII unknowingly used to train or query can cause severe, unintended consequences resulting in financial harm and loss of reputation. Dark data, including PII, is a major problem as LLMs can create associations with published data, creating opportunity for data breaches and leakage. Data poisoning or unintentional biases can easily occur as businesses have poor visibility on what data is used to input or provide feedback for LLMs.
Biased Outputs
Businesses need to be vigilant about using LLMs for activities prone to biases e.g. analyzing resumes for employment fit, automating customer service needs for low income vs high income groups, or forecasting healthcare issues based on gender/age/race. A major issue in AI data training today is due to unbalanced data where one category of data is overwhelmingly dominating other categories leading to bias or incorrect correlations. A typical example would be any dataset with race, age, or gender distributions. Any kind of unbalanced data in these areas could lead to unexpected, unfair outcomes. And if the LLMs are trained by third parties the degree of bias due to these factors is unknown to the LLM consumer.
Explainability & Observability Challenges
For the current set of LLMs hosted publicly, there are only a few prompts available to tie in output results to known input. LLMs can “hallucinate” to create imaginary sources, making observability a challenge. For custom LLMs, businesses can inject observability during training to create associations during the training phase of an LLM. And then it would be possible to correlate the answers to that of the underlying sources to validate the output. Businesses need to have set up bias measurement and monitoring to ensure that the output of LLMs does not lead to harm or discrimination in these scenarios. Imagine harm caused by a LLM-based medical notes summarizer producing different health recommendations for males versus females.
Privacy Rights & Auto-Inferences
As LLMs ingest data, they can create inferences with any personal information categories being provided as customer service records, behavior monitoring, or products considered. Businesses need to ensure that they have appropriate consent as a processor or sub-processor to derive these inferences. It is incredibly hard and expensive for businesses to keep track of privacy data rights and restrict usage in the current setup.
Unclear Data Stewardships
Currently there are no easy, efficient ways for LLMs to unlearn information. The way businesses are using sensitive data as processors or sub-processors makes data stewardship complex to manage. This increases the legal obligations significantly for businesses. For security teams, data inventory, classification, and automation is crucial to design adequate safeguards for AI systems input and output responses. Input data into LLMs for training or prompts need to be filtered to ensure that information used is identified within the scope, for the purpose of use.
Next up: Improving Data Security and Privacy for LLMs
Given these challenges with Large Language Models data security, security teams’ surface areas have increased exponentially and it is much more critical to ensure that LLMs are being used safely and effectively. In the following blogs within this series, we will discuss how to improve privacy and security for LLMs for the following topics:
- Data Discovery: identify risks, detect bias in unstructured, semi-structured and structured data
- Data Classification: establish LLM explainability KPIs, improve data insights based on purpose, residency and scope.
- Setup AI Governance Automation for:
- AI risks posture, preventing bias failures
- Minimize data leaks and automate data security workflows