Growing concerns over data breaches have led to a flurry of data regulations around the world that are aimed at protecting sensitive information about individuals. Through these data laws, organizations are held accountable for how they collect, store, and process data, as such processes can define how an individual can be impacted by a data breach.
Data privacy laws such as the General Data Protection Regulation (GDPR) in Europe and the California Consumer Privacy Act (CCPA) in the United States require businesses to comply with the law if they are located in these regions or serve European or California residents, respectively. Data privacy laws around the world have laid down restrictions for businesses relating to cross-country data transfers, customer consent, data handling practices, and more.
When we specifically talk about CCPA, businesses that do not comply with this law face hefty fines. As the law applies to for-profit organizations that operate in California and meet the below criteria:
- Having annual revenues of $25 million or more
- Buying, selling, receiving, or sharing for commercial purposes the personal data of more than 50,000 consumers per year, or
- Deriving more than 50 percent of annual revenues from the sale of California consumers’ personal information
Privacy and security concerns for product teams
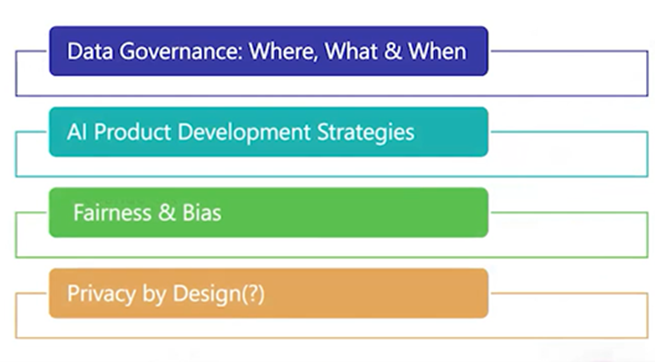
In order to comply with data privacy regulations, it is important to find out where your organization stores customers’ data. CTOs need to take into account their products and see how they are storing this data and if it is structured, semi-structured, or unstructured to further determine where this data is lying. The engineering teams have to account for workflows so they can find data easily.
The second aspect organizations need to consider is classifying the types of data they need and those they don’t. The definition of what is sensitive data and what is personal data is changing very rapidly because laws are continuously changing, and so organizations need to do this in a nimble and agile way. CTOs should stay updated and identify what sensitive information they are storing since the industry definition is constantly changing and they accordingly need to automate their processes.
The last point concerns data drifts. If you have an AI-driven product and encounter unbalanced data, you need to be aware of new data points being introduced and how to detect them. Additionally, if you are collecting or introducing new types of personally identifiable information (PII) or sensitive information, you need to consider how to handle it and determine who has access to it. Keeping these considerations in mind is essential for complying with privacy regulations.
Privacy considerations
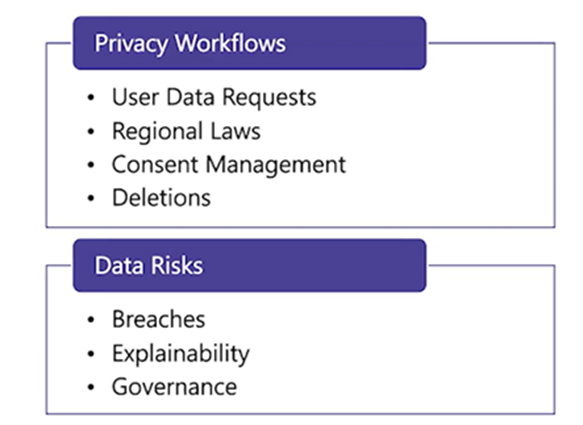
These are the major considerations for handling privacy workflows, and there are four components to them.
- User data requests: Organizations need to handle data requests where users have the right to request deletion of their data, ask for a copy of their data, and opt-in or opt-out.
- Regional laws: Businesses need to comply with the regional laws as they cannot move their customers’ data from one country to another without exclusive consent or without anonymizing the data.
- Consent management: Businesses should display a cookie consent banner on their website to collect users’ data and obtain explicit consent from them.
- Deletions: Developing workflows for requests to delete a user’s personal information.
- Besides the privacy workflows, engineering teams also need to account for data risks.
- Breaches: Today there are a lot of data breaches, and organizations should be prepared in case they fall victim to a data breach. Informing your users about a data breach is important, so you need to plan out this process.
- Explainability: It is important that everyone internally is aware of which data has been breached and how your AI products are working in terms of fairness and bias.
- Governance: The governance aspect refers to who has access to specific data, what they can do with it, which third parties it is shared with, and how you can tackle a data breach efficiently.
Product considerations
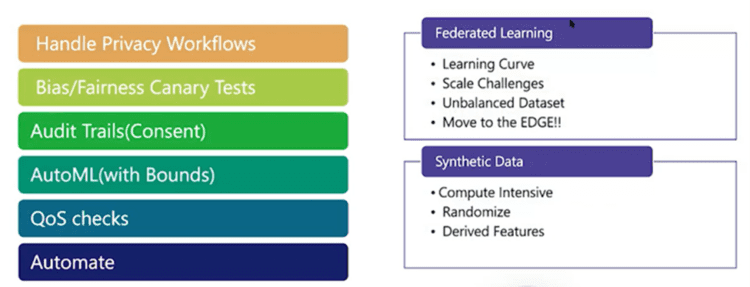
Recommendations for handling privacy workflows or creating them are as follows:
- Handle privacy workflows: Create different types of APIs so that you can give users a copy of their data or delete their data through data discovery.
- Bias/fairness Canary tests: Write canary tests and deploy them to look at the input and output to reach a decision about how fair or biased your models are.
- Audit trails (consent): You need to have very dedicated audit trails to understand where the consent is being tracked and for what features it is being agreed upon.
- AutoML (with bounds): Create auto-ML features for all your products, but with some bounds. So in case there is a data drift, and if it is outside those bounds, then you should take care of those error conditions.
- QoS checks: For each feature release, you need to have quality fairness checks, which will allow product deployment only if the fairness or bias checks are passed.
- Automate: And above all of this, you should automate all of the privacy-related checks and the fairness checks.
Federated learning
If you are a product company using AI, you might need to explore federated learning, where most recommendations and learning occur on the device. Therefore, you need to consider how to transition to a federated learning model and manage the associated scale.
Synthetic data
If you are sharing data with third parties, you need to focus on synthetic data, where you can still share the data easily while not compromising on the quality of the data.
Privacy by design
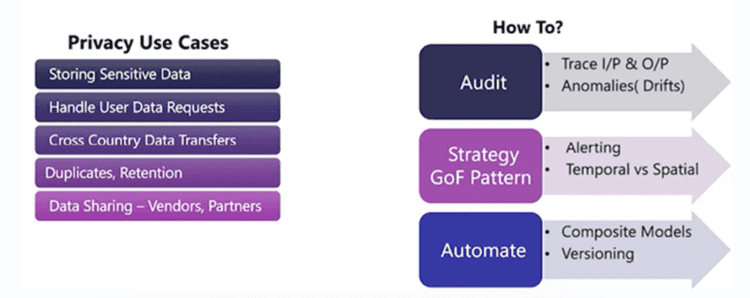
Ultimately, it all comes down to how you use all these principles to approach privacy by design. You need to be aware of how you are storing data, whether you are prepared to comply with different data requests, and whether you have transparent data handling practices within your organization. As long as you have an approach to tackle all these use cases, you will already be implementing privacy by design in your product.
Try to separate this from outside the code by taking the Gang of Four (GoF) pattern strategy, where you inject a strategy and the pattern decides the next steps. Since the privacy laws are changing very quickly, you need to develop a strategy that is more agile and embed the concept of privacy in all your data-processing activities right from the outset.
Can you leverage Secuvy AI to implement privacy by design?
The answer is yes. At Secuvy, we understand the importance of integrating privacy into developing and using products and services and using solutions that facilitate the management of privacy protections. Secuvy’s unified data privacy compliance and data protection platform helps organizations solve both data security and privacy challenges because the platform is built around next-generation self-learning AI.
The first step is to identify and classify data and determine contextual relationships, which opens the door to robust data security and privacy compliance. Our advanced unsupervised machine learning algorithms autonomously analyze immense volumes of data and track them through their lifecycle. Our platform’s ability to learn from and evolve from new data ensures constant refinement of security measures, adapting to the ever-changing threat landscape with remarkable agility.
Our data discovery solution helps you identify structured and unstructured data, including PII and PHI, across your entire IT infrastructure. Once you have complete visibility of your data ecosystem, our contextual data intelligence feature connects data attributes and creates a live data inventory to help you identify what type of data is stored where.
You can automate policy enforcement and monitor them through data risk reports to ensure that all the controls are being followed. Track sensitive data spikes across your data ecosystem and identify trends and at-risk data.
Visit www.secuvy.ai for more information.