1.0 · DISCOVER & CLASSIFY
From “by hand” to automatic classification.
Secuvy reaches 250+ sources and learns what every file is, with no rule sets to write. Your team confirms its recommendations instead of tagging by hand.
Discovery, classification, tagging, and proof, done by software that learns from every correction. First results on your data in 24 hours.
THE BACKLOG
The pipeline is ready and the GPUs are ready. The data is not, because someone has to say what every file is first.
58% of IT leaders call classifying data for AI their hardest technical problem.
Hand work and rule sets fall behind the moment the data shifts, so the classification never stays done.
Secuvy does not use rules. It learns your data on its own and shows first results in 24 hours, not months.
HOW IT WORKS
Both steps run continuously. Nothing is moved.
1.0 · DISCOVER & CLASSIFY
Secuvy reaches 250+ sources and learns what every file is, with no rule sets to write. Your team confirms its recommendations instead of tagging by hand.
2.0 · PROVE
Each pipeline's Data Bill of Materials fills in as data is classified: what went in, what stayed out, and the reason for each choice.
Explore the DBOM →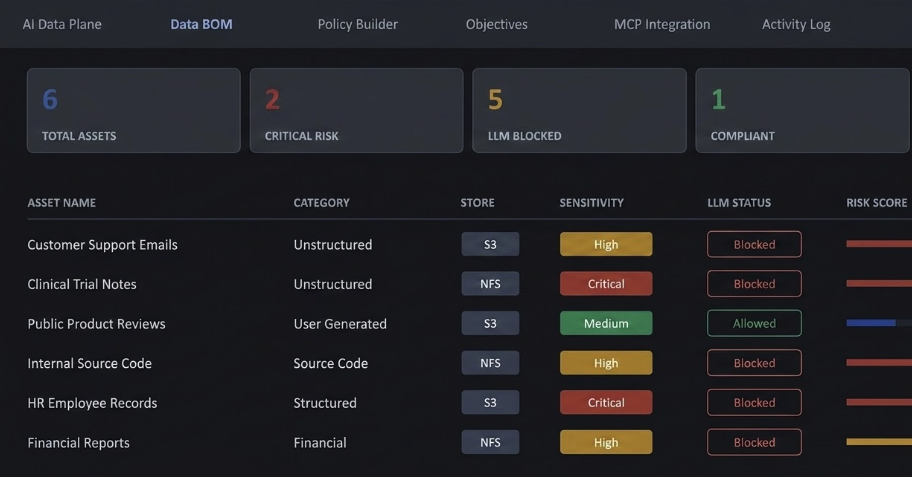
THE FIRST DAY
<1 hr
up and running
<24 hrs
first results on your data
250+
sources supported
0
files moved, changed, or touched
AI data prep takes months because the work is mostly manual: analysts hand-write and tune classification rules, label data, and chase false positives across decades of scattered, unstructured data — then constantly retrain as data changes.
Neither holds at today's scale. People cannot keep up and rules go stale. Secuvy learns without labels, and your team spends its time confirming, not tagging.
It stops being a project. Secuvy is up and running in under an hour, shows first results on your data within 24 hours, and keeps the prep current from then on.
Confidently fuel every AI pipeline.